Course:CPSC522/Stable Diffusion: Image to Prompts
Stable Diffusion: Image to Prompts
Principal Author: Mehar Bhatia, Harshinee Sriram, Nikhil Shenoy
Collaborators:
Abstract
We look at the Image2Prompt Kaggle Competition where the main task is to predict prompts from images. The competition expects us to predict prompts that have a high cosine similarity with the ground truth prompt. The final predictions are made on a hidden test dataset consisting of (prompt, image) pairs. We look at 3 different kinds of approaches, ranging from zero-shot methods to Image Transformer based methods. We compare the performance of these methods on the hidden competition test set and report the cosine similarity scores for each of them. <TODO> write about the best method.
Related Pages
This article is related to Convolutional Neural Networks, Transformer Models, Diffusion Probabilistic Models and Vision Transformers.
Hypothesis
The task in this Kaggle competition is based on the hypothesis that it should be possible to reverse engineer the prompts that were used to generate images using Stable Diffusion 2.0. The diffusion model was run for 50 steps at 768 x 768 px and then downsized to 512 x 512 for the competition dataset. For evaluation, a hidden test-set consisting of 16,000 images is considered where the final score is calculated using cosine similarity.
Cosine Similarity: Measures similarity between two non-zero vectors. It is computed using,
Requirements: The competition requires us to submit a notebook that,
- Runs in <= 9 CPU/GPU hours
- Internet access is disabled (which forbids us from downloading a non-publicly available dataset or adding a custom Python library)
- Uses free and publicly available external data
We test this hypothesis by exploring 3 distinct solutions (which have been further explained in the following sections) that explore the use of a prompt-engineering tool, the concept of transfer learning and the One-For-All (OFA) model respectively.
Approach 1: Clip Interrogator + Sentence Transformer
In this approach we aim to use CLIP Interrogator, a prompt-engineering tool [1] which is a combination of the CLIP [2] (OpenAI) and BLIP [3](Salesforce). The CLIP Interrogator can retrieve the prompt given an image. We can then use the prompt and pass it to a Sentence Transformer to get a 384 dimensional embedding that the competition requires us to submit.
We cover the following two tools and then show results on the test set using this approach,
- Clip Interrogator
- Sentence Transformer
Clip Interrogator

Prompts from Images using Clip Interrogator
CLIPInterrogator uses CLIP and BLIP (covered next) to generate a prompt from an image using the following steps,
- Get a caption from the BLIP model by providing the image as an input
- Get an embedding from the CLIP model by providing the image as an input
- From the prompt database*, find the top-k keywords that have embeddings closest to that of the CLIP embedding. Store the top-k keywords.
- Get the final prompt by joining the caption from Step 1 and the top-k keywords from Step 3.
*Note: Prompt Database is a curated list of texts out of 5 categories (artists, flavors, mediums, movements, negative)
For this approach, we will briefly cover the models CLIP and BLIP.

CLIP: Learning Transferable Visual Models From Natural Language Supervision [2]
CLIP learns image representations by pre-training images and captions using a contrastive loss. They carry out the pre-training task on a large dataset consisting of 400 million image and text pairs collected from the internet. This pre-training allows the CLIP model to develop representations that has a zero shot performance equal to that of ResNet50 on ImageNet.
The architecture for CLIP (also shown graphically in Figure 2) consists of,
- Image Encoder: Takes in image as an input and outputs an N dimensional embedding
- Text Encoder: Takes in caption/description as input and outputs an N dimensional embedding.
For training, CLIP brings together representations from positive image-text pairs closer while pushing away representations of all other pairs. For instance, if we have N pairs of image and text, there would be positive pairs and negative pairs. This can be seen from the matrix in Figure 2 where positive pairs are diagonal elements and negative pairs are off-diagonal elements. This bringing together of positive pairs and pushing away negative pairs is done via a contrastive loss for which the pseudo code [4] has been provided below.
BLIP: Bootstrapping language-image pre-training for unified vision-language understanding and generation[3]

Decoding text from encoder only models like CLIP is not straightforward. BLIP builds upon these limitations and is an improved vision-language model that attains state of the art performance on 7 vision language tasks,
- image-text retrieval
- image captioning
- visual question answering
- visual reasoning
- visual dialog
- zero-shot text-video retrieval
- zero-shot video question answering.
To broadly summarize the model (Figure 3), it consists of 3 objectives and 4 models (with some weight sharing),
- Image Text Contrastive (ITC) Loss: Uses image embeddings from Image Encoder and text embeddings from Text Encoder, and uses a contrastive loss similar to the one used in CLIP.
- Image Text Matching (ITM) Loss: Using a Image-Grounded Text Encoder, it develops an embedding by taking text as input and conditioning it with the image embeddings from the Image encoder (therefore image grounding). This loss is a simple binary classification loss with 1 for positive pairs and 0 for negative pairs.
- Language Modelling (LM) Loss: Using a Image-Grounded Text Decoder, it generates text using image embeddings from the Image Encoder. The loss is language modelling loss.
Sentence Transformer[5]
Sentence Transformer is a model used for state of the art embeddings from text. It can be used to retrieve embeddings from over 100 languages. We use this model to retrieve embeddings from the prompt generated from CLIP Interrogator.
Experiment Results
We perform several experiments to show the utility of CLIP Interrogator,
Note*: Artists consists of actual names and is a long list, so we do not include the keywords in the ablation experiments from that.
| Experiment Type | Flavours | Mediums | Movements | Cosine Similarity on Test |
|---|---|---|---|---|
| Only BLIP prompt | 0 | 0 | 0 | 0.4143 |
| BLIP Prompt + | 1 | 1 | 1 | 0.4514 |
| BLIP Prompt + | 2 | 1 | 1 | 0.4583 |
| BLIP Prompt + | 1 | 2 | 1 | 0.4454 |
| BLIP Prompt + | 1 | 1 | 2 | 0.4476 |
| BLIP Prompt + | 3 | 1 | 1 | 0.4584 |
Approach 2: Transfer Learning with a Vision Transformer (ViT) + Sentence Transformer
The second approach involves using a Vision Transformer (ViT) model that has been trained on ImageNet-21k[6][7] with 14 million images and 21,843 classes at a resolution of 224x224. This model is then fine-tuned on ImageNet 2012[8], which has 1 million images and 1,000 classes at the same resolution. The model is then further trained with transfer learning on the Diffusion DB 2 million dataset [9][10], which has 2 million images created by Stable Diffusion based on user-specified prompts and hyperparameters. Finally, the model generates prompt embeddings that are in the form of 384-dimensional embeddings required for the competition using a Sentence Transformer, similar to the previous approach. This solution is described in detail in the following subsections, which outline the step-by-step process. The first section covers the preprocessing of the Diffusion DB dataset, followed by an explanation of the ViT model and the transfer learning process used in this solution, and concludes with the inference section.
Diffusion DB dataset pre-processing
This step involves processing the Diffusion DB image metadata. We begin by reading the Diffusion DB metadata file in a Parquet format and selecting columns that contain image names, prompts, width, and height. Next, we filter the metadata to keep only the images with a width and height of 512 pixels. This is followed by cleaning up the prompt column by removing leading and trailing spaces, and removing prompts with fewer than five words or containing invalid characters. After this, the first and last 15 characters of the prompt text are extracted and duplicate entries are removed based on the substrings. The last part involves adding file paths to the DataFrame by looping over image directories and matching file names to image names in the DataFrame and then saving the resulting DataFrame as a .csv file.
Training
The training process involves taking a pre-trained ViT ('vit_base_patch16_224'[11]) and training it further with the preprocessed Diffusion DB dataset. During training, the average loss and cosine similarity for each batch of data are calculated and at the end of each epoch, the average loss and cosine similarity for the entire training and validation sets are calculated. Then, the best model based on the validation cosine similarity score is saved.
The ViT
Transformers, in comparison to Convolutional Neural Networks (CNNs)[12], lack certain built-in assumptions or biases, such as the ability to recognize objects regardless of their position or appearance, and having a limited area of focus for image analysis. This difference is due to the fact that CNNs rely on a linear local operator called convolution, which only considers adjacent values based on the kernel used, whereas transformers are designed to be permutation invariant, meaning they are not limited by the arrangement of inputs. Additionally, transformers cannot process grid-structured data and require sequential data instead. Hence, ViTs were introduced in the work by Dosovitskiy et al. (2020)[13], to convert spatial non-sequential data (images) into sequences.


Figure 4 depicts the architecture of this ViT, which closely follows the architecture of the original Transformer that was introduced in the work by Vaswani et al. (2017)[14]. Processing images with a ViT consists of a couple of steps. First, an image is divided into smaller patches, which are then flattened and transformed into lower-dimensional linear embeddings. Next, positional embeddings are added to these embeddings to retain spatial information. This sequence of embeddings is then passed through a typical transformer encoder and the output of this encoder is sent to the final MLP head for classification. Click here to view a .GIF file that animates the entire process. In essence, image patches are equivalent to sequence tokens, similar to words. The encoder block used in the architecture is the same as the original transformer introduced by Vaswani et al. (2017), with the only difference being the number of transformer encoder blocks utilized (Figure 5 shows the architecture of a transformer encoder block).
{kind=link}
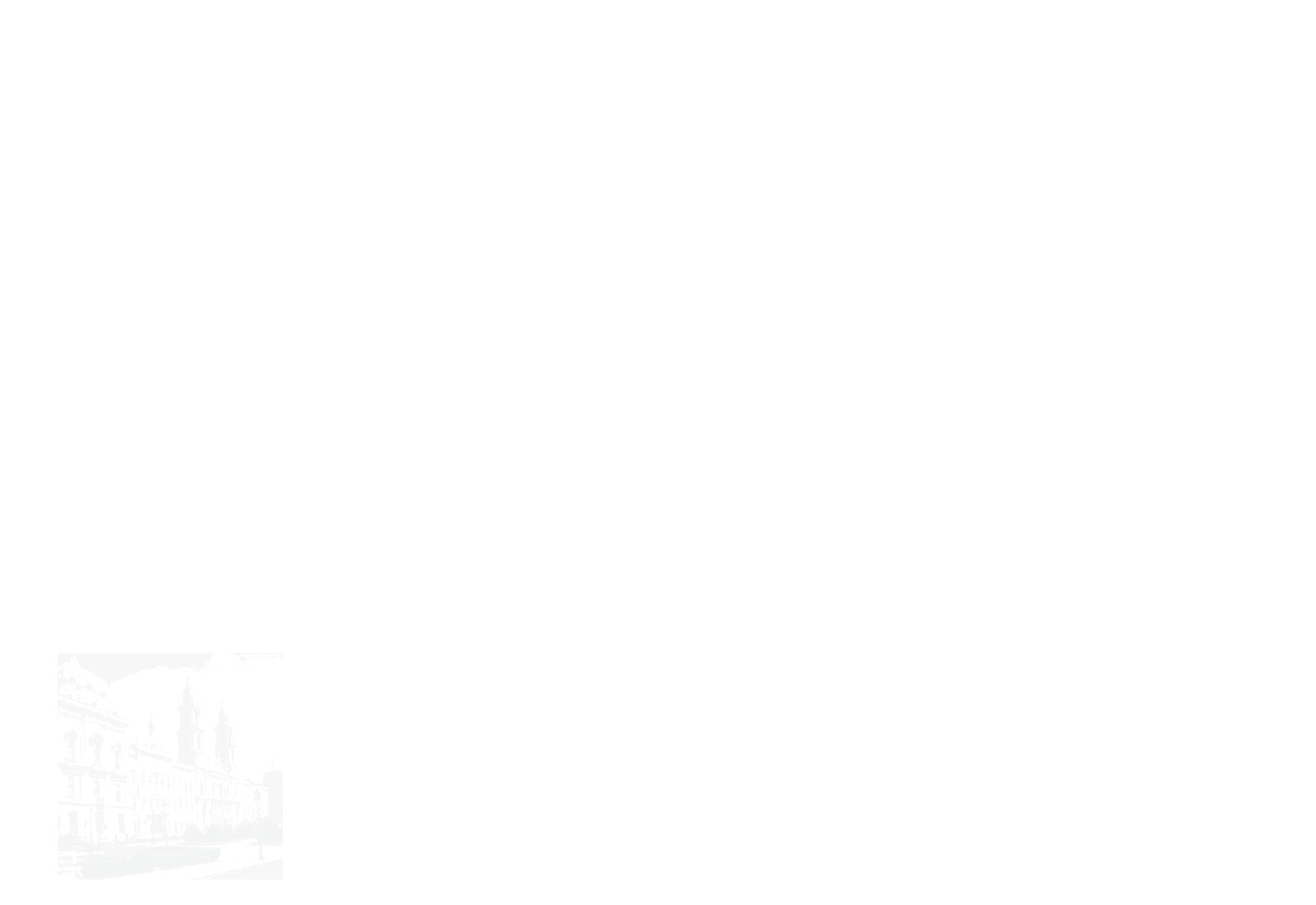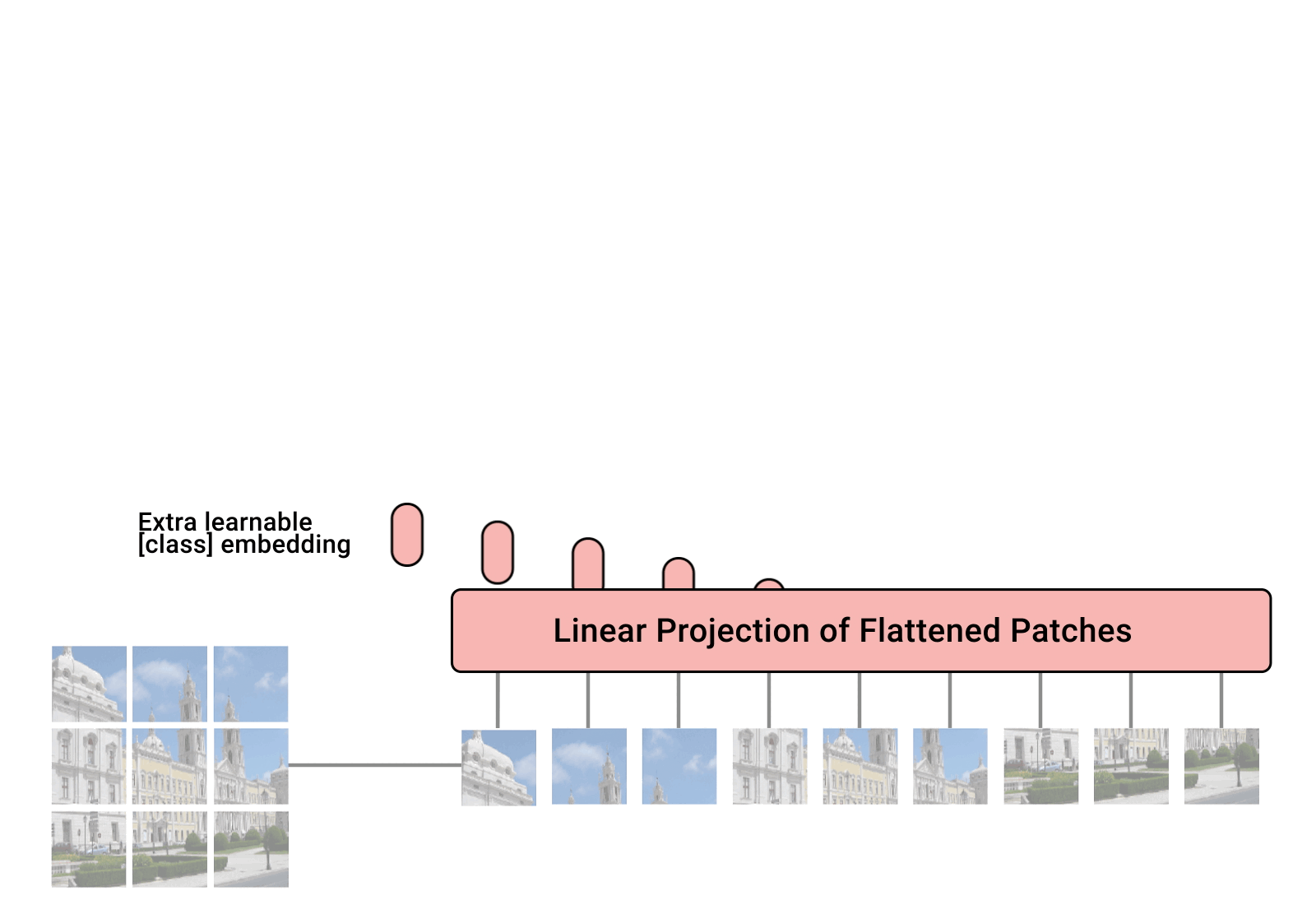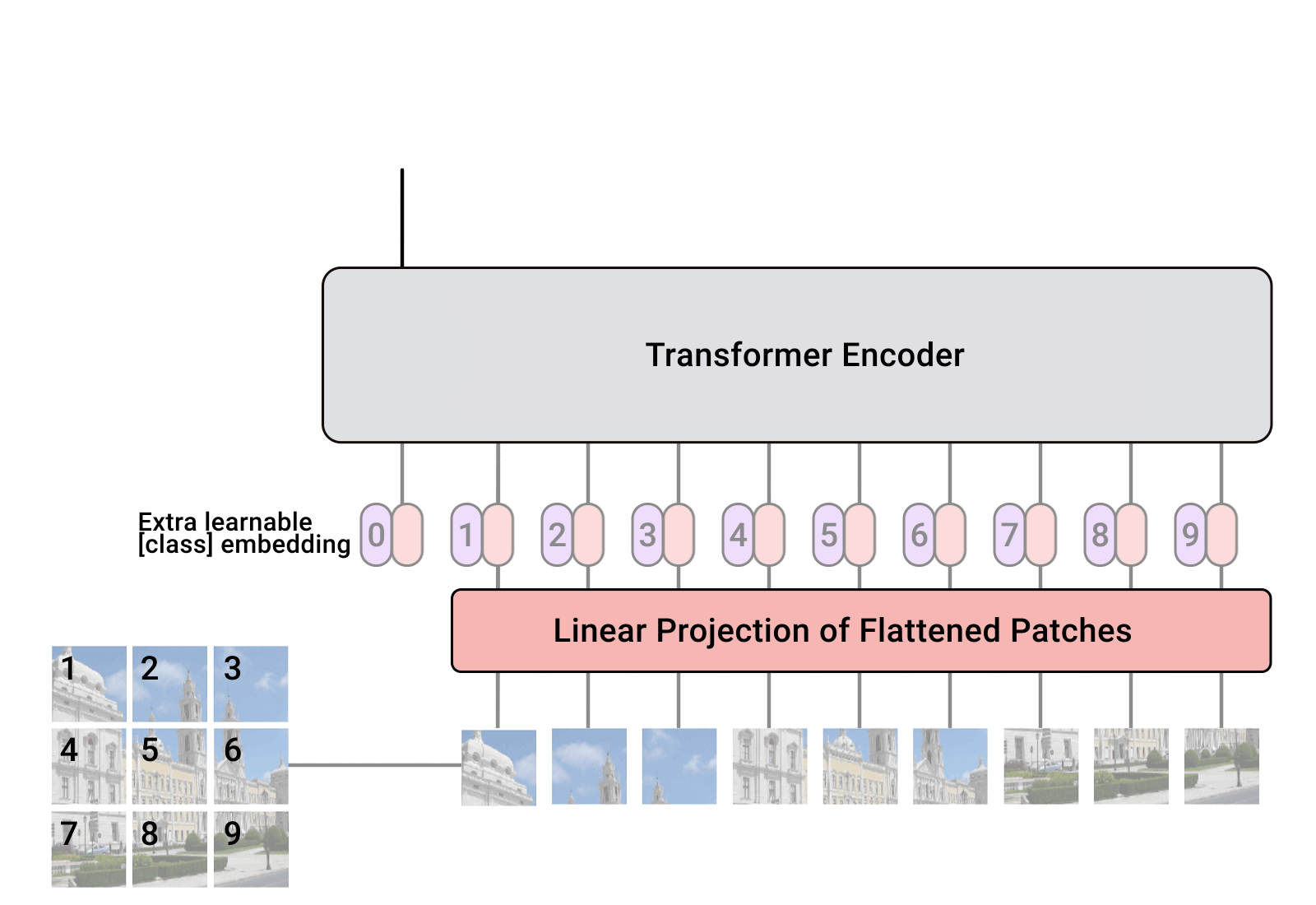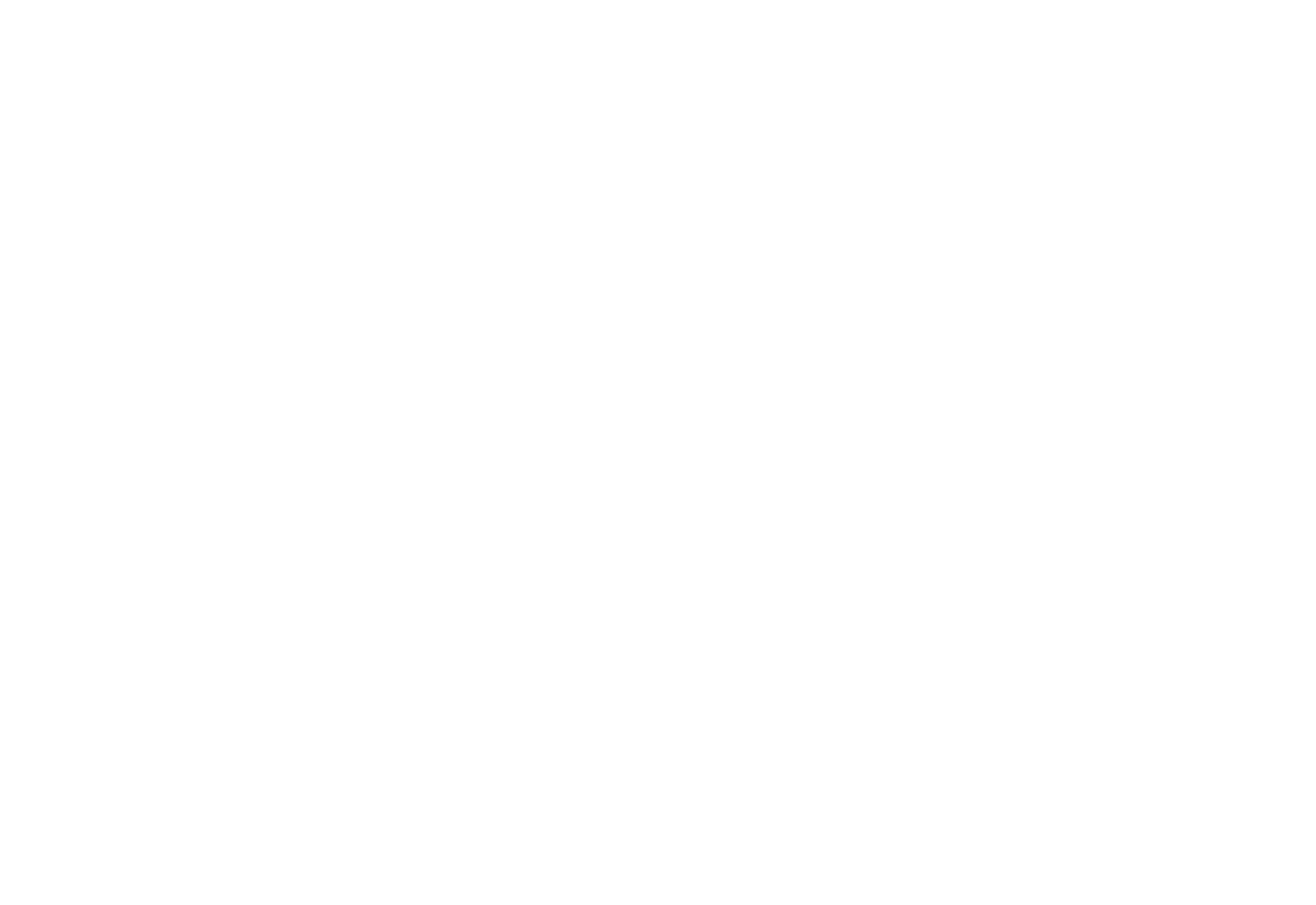{kind=link}
{kind=link}
In order to demonstrate the possibility of training larger ViT variations with more data, three ViT variants were introduced in the work by Dosovitskiy et al. (2020) (see Table 1). The table shows various parameters used in the Transformer Encoder block of the architecture. Heads refer to the number of parallel attention heads, and MLP size refers to the size of the MLP component inside the transformer encoder block (Figure 5). The Hidden size D is the embedding size and it remains fixed across all the layers so that short residual skip connections can be used. The architecture doesn't include a decoder, but there is an additional linear layer for the final classification called MLP head. The authors tested these pre-trained ViT variations against other ResNet models and found the former to outperform the latter for all selected benchmark datasets (see Table 2). For our solution, we selected the pre-trained ViT-Base model.
{kind=link}
{kind=link}
Transfer Learning
Transfer learning[15] is a technique in machine learning where a model trained on one task can be utilized for a different but related task. The aim of transfer learning is to enable faster progress or better performance when modeling the second task. For transfer learning to work in deep learning, the model features learnt from the first task must be generalizable. This form of transfer learning is known as inductive transfer, where the model bias is constrained in a beneficial way by using a model trained on a different but related task. As mentioned earlier, our solution uses a pre-trained Vision ViT (vit_base_patch16_224) to extract features from input images. We apply transfer learning on the Diffusion DB dataset, which contains prompts for various images and the resulting model is fine-tuned to predict the corresponding prompt for an image given as input.
The training process
For training, we define a collator function called DiffusionCollator that encodes the prompts using the pre-trained all-MiniLM-L6-v2 Sentence Transformer model[16][5] that maps sentences to a 384-dimensional dense vector space. The dataloader is then created using these dataset and collator functions. The train function trains the Vision Transformer model using cosine embedding loss[17] and the AdamW[18] optimizer. The best model is saved based on its cosine similarity score. The learning rate scheduler used is a cosine annealing scheduler[19]. During training, the model is first passed an image to extract its features, and then the extracted features are passed through a fully connected layer with 384 output neurons. The output of this fully connected layer is then sent through the collator function to generate the prompt embeddings. The cosine similarity between the predicted prompt embeddings and the ground truth embeddings is then calculated and minimized using backpropagation.
Inference
The process of converting embeddings back to text is called decoding. Decoding involves generating text based on a language model's learned representations, which can be challenging without the right tools. The all-MiniLM-L6-v2 and vit_base_patch16_224 models are pre-trained language models that are optimized for generating high-quality embeddings, but they do not come with decoders. Without a decoder, it is difficult to convert the predicted prompt embeddings back to text. Therefore, to convert predicted prompt embeddings back to English text using the all-MiniLM-L6-v2 and vit_base_patch16_224 models, future work will involve training a separate decoder that is compatible with these embedding models.
Experiment Results
To assess this solution, we submitted the embeddings generated for the test set to Kaggle and received a mean cosine similarity score of 0.5062 for our approach, implying that this is a promising solution to address the task of generating prompts from images.
Approach 3: OFA + Sentence Transformers
For the third approach, we cover the two tools and then show results on the test set using this approach,
- OFA Model
- Sentence Transformer
OFA Model
OFA (One-for-All) is a unified task-agnostic and modality-agnostic framework leveraging a sequence-to-sequence learning approach to learn a single neural architecture. OFA model also supports Task Comprehensiveness and is the first attempt to unify vision & language, vision-only and language-only tasks, including understanding and generation. OFA is pre-trained on a total of 20M publicly available cross-modal data and 140GB plain text, and achieves state-of-the-art performances in a series of vision & language downstream tasks, including image captioning, visual question answering, visual entailment, referring expression comprehension, etc as shown in Figure 6. Additionally, OFA achieves competitive performance in zero-shot learning and can transfer to unseen tasks with new task instructions and adapt to out-of-domain information without fine-tuning. Table 3 shows the statistics on the datasets for respective pre-training tasks.


The most common practice of multimodal pre-training is the pre-training of Transformer models on image-text pair corpus at scale. This requires data preprocessing or modality-specific adaptors to enable the joint training of both visual and linguistic information with the Transformer architecture. Compared with the complex, resource & time-consuming object feature extraction, the authors directly use ResNet modules to convolve patch features of the hidden size, following approaches like CoAtNet[20] and SimVLM[21]. As to processing the linguistic information, similar to the practice of GPT[22] and BART[23], the authors apply byte-pair encoding (BPE)[24] to the given text sequence to transform it into a subword sequence and then embed to features.
To process different modalities without task-specific output schema, it is essential to represent data of various modalities in a unified space. A possible solution is to discretize text, image, and object and represent them with tokens in a unified vocabulary. An effective approach to reduct the sequence length of image representation is sparse coding. For example, an image of the resolution of 256 x 256 can represented as a code sequence of the length of 16 x 16. Each discrete code strongly correlates with the corresponding patch[25]. Apart from representing images, it is also essential to represent objects within images as there are a series of region related tasks. Following Pix2Seq[26], objects are represented as a sequence of discrete tokens by extracting its bounding box and label. The continuous corner coordinates (the top left and the bottom right) of the bounding box are uniformly discretized to integers as location tokens, and the object labels are represented with BPE tokens. A unified vocabulary is used for all the linguistic and visual tokens, including subwords, image codes, and location tokens.
Overview of Architecture
Following the previous successful practices in multimodal pre-training[27][28], OFA model as well uses Transformer as the backbone architecture, and adopts the encoder-decoder framework as the unified architecture for all the pre-training, fine-tuning, and zero-shot tasks. Specifically, both the encoder and the decoder are stacks of Transformer layers. A Transformer encoder layer consists of a self attention and a feed-forward network (FFN), while a Transformer decoder layer consists of a self attention, an FFN and a cross attention for building the connection between the decoder and the encoder output representations. To stabilize training and accelerate convergence, head scaling to self attention is added, followed by a post-attention layer normalization (LN)[29], and an LN following the first layer of FFN [30]. For positional information, two absolute position embeddings for text and images are used respectively. Instead of simply adding the position embeddings, the architecture follows decoupling of the position correlation from token embeddings and patch embeddings[31]. In addition, 1D relative position bias for text[32] and 2D relative position bias for image [20][21] is used.
Image Captioning with OFA Model
For our task, we use the OFA model and infer the captions with the help of a question prompt asking the model to describe the image.
Sentence Transformers
Similar to the above two approaches, we use a sentence transformer to extract a vector representation of that sentence. The main advantage of sentence transformers is that they capture the meaning of a sentence in a more nuanced way than traditional bag-of-words models or other simpler representations. They can take into account the context and the relationships between words in a sentence, allowing for more accurate and effective analysis of text. We use all-MiniLM-L6-v2 model which is based on LM architectures such as BERT[33] or GPT-2[22] with six transformer layers.
Experiment Results
Using this approach, we received a mean cosine similarity score of 0.42644.
Approach 4: Ensemble Model using CLIPInterrogator+OFA+ViT
After comparing performance using the above three approaches, we design a final approach which ensembles the CLIP Interrogator, OFA model and ViT model as follows,
- We use CLIP Interrogator, ViT model and OFA model in equal ratio.
- Embeddings3: Follow Approach 3 to load the OFA model and use the prompt "What does the image describe?" to generate relevant captions. Use the Sentence Transformer to convert the captions into embeddings after removing stopwords.
- Embeddings1: Follow Approach 1 using CLIP Interrogator to retrieve the prompt given an image and passing it to a Sentence Transformer to get a 384 dimensional embedding.
- Embeddings2: Follow Approach 2 to directly retrieve embeddings using pre-trained Vision ViT (vit_base_patch16_224)
- Extract ensemble embeddings i.e, (ratio_OFA * embeddings3) + (ratio_CLIP_Interrogator * embeddings1) + (ratio_ViT * embeddings2)
To assess this solution, we submitted the ensemble embeddings generated for the test set to Kaggle and receive a mean cosine similarity score of 0.55161 for our approach, implying the advantages of combining these approaches as an ensemble as a promising solution.
Conclusions
The following presents the best test set mean cosine similarity results from each approach:
| Approach | Mean cosine similarity score |
|---|---|
| Approach 1: CLIP interrogator | 0.4584 |
| Approach 2: Transfer Learning with a Vision Transformer | 0.5062 |
| Approach 3: OFA Model | 0.4264 |
| Approach 4: Ensemble Model (CLIPInterrogator+OFA+ViT) | 0.5516 |
We conclude that the ensemble method (combining the three above approaches) provides more accurate predictions than each of the individual approaches on the hidden test set. The ensemble smooths out the errors and biases of any individual model, resulting in a more robust and accurate prediction, with improved generalization on unseen data. A strong future work direction involves optimizing and possibly even simplifying this resulting ensemble architecture to one streamlined architecture.
Annotated Bibliography
Put your annotated bibliography here. Add links where appropriate.
|
|
- ↑ https://github.com/pharmapsychotic/clip-interrogator
- ↑ 2.0 2.1 @inproceedings{radford2021learning, title={Learning transferable visual models from natural language supervision}, author={Radford, Alec and Kim, Jong Wook and Hallacy, Chris and Ramesh, Aditya and Goh, Gabriel and Agarwal, Sandhini and Sastry, Girish and Askell, Amanda and Mishkin, Pamela and Clark, Jack and others}, booktitle={International conference on machine learning}, pages={8748--8763}, year={2021}, organization={PMLR} }
- ↑ 3.0 3.1 @inproceedings{li2022blip, title={Blip: Bootstrapping language-image pre-training for unified vision-language understanding and generation}, author={Li, Junnan and Li, Dongxu and Xiong, Caiming and Hoi, Steven}, booktitle={International Conference on Machine Learning}, pages={12888--12900}, year={2022}, organization={PMLR} }
- ↑ https://amaarora.github.io/posts/2023-03-06_Understanding_CLIP.html
- ↑ 5.0 5.1 @article{reimers2019sentence, title={Sentence-bert: Sentence embeddings using siamese bert-networks}, author={Reimers, Nils and Gurevych, Iryna}, journal={arXiv preprint arXiv:1908.10084}, year={2019} }
- ↑ Ridnik, Tal, Emanuel Ben-Baruch, Asaf Noy, and Lihi Zelnik-Manor. "Imagenet-21k pretraining for the masses." arXiv preprint arXiv:2104.10972 (2021).
- ↑ https://github.com/Alibaba-MIIL/ImageNet21K
- ↑ https://www.image-net.org/challenges/LSVRC/2012/#
- ↑ Wang, Zijie J., Evan Montoya, David Munechika, Haoyang Yang, Benjamin Hoover, and Duen Horng Chau. "DiffusionDB: A Large-scale Prompt Gallery Dataset for Text-to-Image Generative Models." arXiv preprint arXiv:2210.14896 (2022).
- ↑ https://github.com/poloclub/diffusiondb
- ↑ https://huggingface.co/google/vit-base-patch16-224
- ↑ Course:CPSC522/Convolutional Neural Networks
- ↑ Dosovitskiy, Alexey, Lucas Beyer, Alexander Kolesnikov, Dirk Weissenborn, Xiaohua Zhai, Thomas Unterthiner, Mostafa Dehghani et al. "An image is worth 16x16 words: Transformers for image recognition at scale." arXiv preprint arXiv:2010.11929 (2020).
- ↑ Vaswani, Ashish, Noam Shazeer, Niki Parmar, Jakob Uszkoreit, Llion Jones, Aidan N. Gomez, Łukasz Kaiser, and Illia Polosukhin. "Attention is all you need." Advances in neural information processing systems 30 (2017).
- ↑ https://en.wikipedia.org/wiki/Transfer_learning
- ↑ https://huggingface.co/sentence-transformers/all-MiniLM-L6-v2
- ↑ https://pytorch.org/docs/stable/generated/torch.nn.CosineEmbeddingLoss.html
- ↑ https://pytorch.org/docs/stable/generated/torch.optim.AdamW.html
- ↑ https://pytorch.org/docs/stable/generated/torch.optim.lr_scheduler.CosineAnnealingLR.html
- ↑ 20.0 20.1 Dai, Zihang, et al. "Coatnet: Marrying convolution and attention for all data sizes." Advances in Neural Information Processing Systems 34 (2021): 3965-3977.
- ↑ 21.0 21.1 Wang, Zirui, et al. "Simvlm: Simple visual language model pretraining with weak supervision." arXiv preprint arXiv:2108.10904 (2021).
- ↑ 22.0 22.1 Radford, Alec, et al. "Improving language understanding by generative pre-training." (2018).
- ↑ Lewis, Mike, et al. "Bart: Denoising sequence-to-sequence pre-training for natural language generation, translation, and comprehension." arXiv preprint arXiv:1910.13461 (2019).
- ↑ Sennrich, Rico, Barry Haddow, and Alexandra Birch. "Neural machine translation of rare words with subword units." arXiv preprint arXiv:1508.07909 (2015).
- ↑ Bao, Hangbo, et al. "Beit: Bert pre-training of image transformers." arXiv preprint arXiv:2106.08254 (2021).
- ↑ Chen, Ting, et al. "Pix2seq: A language modeling framework for object detection." arXiv preprint arXiv:2109.10852 (2021).
- ↑ Chen, Yen-Chun, et al. "Uniter: Universal image-text representation learning." Computer Vision–ECCV 2020: 16th European Conference, Glasgow, UK, August 23–28, 2020, Proceedings, Part XXX. Cham: Springer International Publishing, 2020.
- ↑ Zhang, Pengchuan, et al. "Vinvl: Revisiting visual representations in vision-language models." Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. 2021.
- ↑ Ba, Jimmy Lei, Jamie Ryan Kiros, and Geoffrey E. Hinton. "Layer normalization." arXiv preprint arXiv:1607.06450 (2016).
- ↑ Shleifer, Sam, Jason Weston, and Myle Ott. "Normformer: Improved transformer pretraining with extra normalization." arXiv preprint arXiv:2110.09456 (2021).
- ↑ Ke, Guolin, Di He, and Tie-Yan Liu. "Rethinking positional encoding in language pre-training." arXiv preprint arXiv:2006.15595 (2020).
- ↑ Raffel, Colin, et al. "Exploring the limits of transfer learning with a unified text-to-text transformer." The Journal of Machine Learning Research 21.1 (2020): 5485-5551.
- ↑ Devlin, Jacob, et al. "Bert: Pre-training of deep bidirectional transformers for language understanding." arXiv preprint arXiv:1810.04805 (2018).