Course:CPSC522/Conditional GANs for Image to Image Translation
Title
Conditional Generative Adversarial Networks offer a general-purpose solution to solve image-to-image translation tasks.
Principal Author: Michela Minerva
Collaborators: -
Abstract
Conditional Generative Adversarial Networks (cGANs) [1] are a specific type of Generative Adversarial Networks (GANs) [2] in which the generation of data is performed in a conditional setting. In cGANs output generation is performed in a similar way to normal GANs, but it is conditioned on input data. The characteristics of cGANs make them a powerful tool for solving the general purpose image-to-image translation task, where the generation of an output image is conditioned on a given input image. It is possible to use the same network architecture and objective, but train on different data, to obtain systems that solve different image-to-image translation problems. Moreover, cGANs can be included in more complex generative systems such as cycleGANs.
This page describes cGANs and, in particular, refers to one of the first cGANs successfully used for image-to-image translation: Pix2Pix [3]. Then it shows some results of image-to-image translation problems solved with this model.
Builds on
This page builds on concepts related to deep learning, in particular Generative adversarial Networks; Course:CPSC522/Generative Adversarial Networks is another page that treats GANs. It focuses on deep learning techniques computer vision problems, in particular to the task of image-to-image translation.
Related Pages
Course:CPSC522/Generative Adversarial Networks talks about GANs in general and focuses on an application of these architectures.
Content
Introduction and background
Image-to-Image translation
Image-to-image translation is the task of translating a given image into a corresponding output image. It can be viewed as a generative problem, where the output image is generated in a controlled way, conditioned by the input image. Automatic image-to-image translation is “the task of translating one possible representation of a scene into another, given sufficient training data” [3].
Several problems in image processing, computer vision and computer graphics can be formulated as image-to-image translations. Examples of applications of image-to-image translation are style transfer, season transfer, object transfiguration, image colorization, generation of semantic labels from images[3], image super-resolution[4] and domain adaptation[5]. These problems can be solved using application-specific methods, resulting in highly-specialized models. However, they are all instances of the same problem, that can be reduced to the task of mapping pixels to pixels. For this reason it is useful to study a general purpose technique that allows one to use the same architecture and loss function for several specific applications. Conditional GANs can be useful for this purpose.
GANs

Generative Adversarial Networks (GANs)[2] are a class of machine learning methods for training generative models. The typical architecture of a GAN is composed of two neural networks:
- A generator (G) that generates new convincing samples; it tries to make them indistinguishable from real samples
- A discriminator (D) that classifies each given sample as either fake (i.e. synthesized by the generator) or real.
During the training process, these two models are trained together in an adversarial fashion. The generator tries to synthesize images that fool the discriminator, and the discriminator tries to distinguish the generator’s outputs from real images. In this setting, improvements in the discriminator come at the cost of a reduced capability of the generator and viceversa .
GANs overcome a major issue of conventional Neural Networks (NNs), i.e. the need of finding an effective loss specific for the task. In NNs, the learning process is automatic, but the proper loss for the task must be designed manually. On the other hand, it is possible to formulate the high-level aim of a GAN as the general task of synthesizing data that is indistinguishable from reality. This is the general aim of a whole GAN network, and the loss function adopted in conventional GANs derives from this goal. During training, the GAN learns a loss appropriate for discriminating whether an image is real or fake (discriminator), and it simultaneously trains a generative model to minimize this loss (generator). GANs learn a loss that adapts to training data, hence they can be applied to a broad set of tasks that require different loss functions.
Conditional GANs
From GANs to cGANs
GANs have been successfully used for image synthesis, for generating new examples of images for a given dataset. However, GANs provide no control on modes of the data in the output domain; conditioning the model on additional inputs allows one to direct the data generation process.[1]
While GANs learn a generative model of data, conditional Generative Adversarial Networks (cGANs) learn a conditional generative model. A simple example of conditioning in computer vision can be image generation conditioned on a class label; this allows one to synthesise output images of a given type, controlled by the class label input.
Conditional GANs are trained so that both the generator and the discriminator are conditioned on an input image. When the trained generator model is used to synthesize an image in the output domain, it is conditioned on an input image and it generates a corresponding output image. “Generative adversarial nets can be extended to a conditional model if both the generator and discriminator are conditioned on some extra information x. […] We can perform the conditioning by feeding x into both the discriminator and the generator as additional input layer” [1]. This makes cGANs useful for image-to-image-translation tasks; the translation is performed between an input image, that conditions the generator, and a output image also called target image.

In this setting:
- The generator G is given an input image , and synthesizes a translated version of the image belonging to the output domain
- The discriminator D is given an input image and a real or synthesized paired image , and must determine if this pared image is real or fake.
The generator model is trained to fool the discriminator, like in classic GANs, but also to minimize the loss between the generated image and the expected target image. Hence the training process requires a dataset of pairs; each pair consists of one input image and the relative target image. The reason for this choice is explained later in this page.
The first successful image-to-image translation cGAN is named Pix2Pix [3]. In this architecture, both the generator and the discriminator are neural networks. In particular:
- The generator is a U-Net[7], i.e. an encoder-decoder network with skip connections. In Pix2pix, noise is provided to the generator in the form of dropout in the network; the input image is the actual input of the encoder-decoder network.
- The discriminator is a PatchGAN.
Objective function
A GAN is a generative model that learns a mapping from a random noise vector to the output image :
A conditional GAN learns a mapping between the input image and the random noise vector to the output image :
Despite the introduction of the input , the noise is still necessary for the generator. Without , the network still learns a mapping from to . However, in this setting the output of the model is deterministic given because of the absence of the input .
The loss function for a conventional GAN is:
The behaviour of a GAN can be interpreted as a minmax game:
- should be high for real samples [], from the discriminator's (D) persective, and does not depend on the generator (G)
- should be low for fake samples[], from D's persective
- should be high for fake samples[], from G's persective.
The objective function to optimize is:
Adding the conditioning turns the loss into cGAN’s loss function:
Pix2Pix implements a possible objective function for image-to-image translation with GANs. The adversarial objective is mixed with a traditional loss, such as L1 or L2 distance. In this setting, the discriminator is the same as a conventional cGAN. The generator aims at fooling the discriminator (cGAN loss), but also at producing images close to the groundtruth according to the L1/L2 loss. The loss adopted in Pix2Pix is the L1 loss:
The resulting objective function that the cGAN Pix2Pix[3] optimizes is:
where is a parameter that controls the effect of the L1 and the GAN terms in the loss. Both the components of this objective are important. Using L1 alone produces reasonable but blurry output images. On the other hand, using the cGAN objective alone, the results are sharper but can have visual artifacts [3].
Optimization
The optimization procedure for cGANs follows the original GAN's training approach [2], using gradient descent. It alternates between one gradient descent step on the discriminator and one step on the generator. In practice, instead of training the generator to minimize , it is trained to maximize .
Applications and results
Conditional GANs, and in particular Pix2Pix, have been successfully applied in many image-to-image translation tasks. Here there are some examples from the original paper[3]:
- From street labels to street photograph. This mapping translates from a label map to a corresponding image

Cityscapes labels to street photograph - From street photograph to street label (semantic segmentation) It is possible to notice that cGANs can translate in both directions between the two domains, althought a different model is required for each translation.

Semantic Segmentation - From map to aerial photo and vice versa.
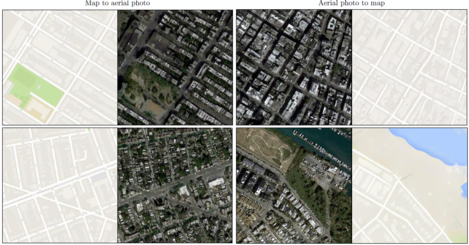
Map to aerial photo and aerial photo to map - From day to night photograph

Day to night photograph - From edges to photograph. The two examples show that the cGAN works both with detected edges and with hand-drawn edges; the results are not very plausible in the latter case, due to the unlikely shape of the edges.

Detected edges to photograph 
Hand-drawn edges to photograph - From thermal map to color RGB image

Thermal map to RGB image







Discussion and conclusions
Advantages and disadvantages of cGANs
The use of conditional GANs to solve image-to-image translation tasks has both advantages and disadvantages.
Advantages:
- CGANs condition the model on additional inputs. This allows one to direct the data generation, providing control on modes of the synthesized data.
- CGANs require less human intervention in the process of building the model compared to standard Neural Networks, since there is no need to define an hand-crafted loss for each specific task.
- The method is completely general and the field of application is really wide. These networks learn a loss adapted to the task and to the data provided during training, which makes them applicable in a wide variety of settings. The Pix2pix framework has been applied to a large variety of image-to-image translation tasks, far beyond the scope of the original paper[3].
Disadvantages:
- CGANs appear to be effective on problems where the output is highly detailed or photographic. On the other hand, in vision problems like semantic segmentation, where the output is less complex than the input, they appear to have a worse performance compared to already existing methods[3].
- CGANs can only be used for paired image translation, i.e. the training set consists of pairs of images from the input and the target domain. Other methods have been developed to deal with unpaired image translation.
- A cGAN model is specific for a particular couple of domains, the ones used during the training process. In other words, the translation performed by cGANs is limited to two domains, one for the input and one for the target image. For every pair of image domains, a specific model must be trained.
Discussion and future works
Conditional Generative Adversarial Networks are a powerful tool and can be applied to several image-to-image translation tasks in computer vision and computer graphics. They are a general-purpose method and allow one to use the same architecture and loss function for different problems; what changes between two distinct problems is only the data used for training the cGAN. Moreover, they do not require the tedious process of defining the loss, typical of Neural Networks' design.
Being such a powerful and general-purpose tool, cGANs are suitable for arbitrary image-to-image translation tasks and they can be exploited in larger machine learning frameworks.
An important future work after Pix2Pix is represented by CycleGAN [8]. A problem in cGANs is that they require paired image translation, i.e. the training data must consist of pairs of input and target images. CycleGAN tries to solve the task of unpaired image translation; the aim is to learn a mapping between two sets of images (one set for the source and one set for the target) that don’t have any correspondence.
Another work on image-to-image translation that goes beyond cGANs is StarGAN [9]. Conditional GANs like Pix2Pix perform translation between images in two domains; different models must be built independently for every pair of image domains. StarGAN is a more scalable GAN framework that performs image-to-image translations for multiple domains using only a single model. It can deal with image translation to various target domains by providing conditional domain information.
Conditional GANs are a general tool and have also found application outside the task of image-to-image translation. Examples of these applications are:
- Test-to-image synthesis [10][11]
- Convolutional face generation[12]
- Face aging[13]
- Video generation[14]
- Shadow detection in images[15]
Annotated Bibliography
- ↑ 1.0 1.1 1.2 Mirza, M (2014). "Conditional Generative Adversarial Nets". Cite journal requires
|journal=(help) - ↑ 2.0 2.1 2.2 Goodfellow, I.J. (2014). "Generative adversarial nets" (PDF). NIPS’2014.
- ↑ 3.00 3.01 3.02 3.03 3.04 3.05 3.06 3.07 3.08 3.09 3.10 Isola, P. (2016). "Image-to-Image Translation with Conditional Adversarial Networks". CVPR 2017.
- ↑ Ledig, C. (2017). "Photo-realistic single image super-resolution using a generative adversarial network". CVPR 2017.
- ↑ Murez, Z. (2017). "Image to Image Translation for Domain Adaptation". CVPR 2017.
- ↑ Gharakhanian, Al. "GANs: One of the Hottest Topics in Machine Learning".
- ↑ Ronneberger, O. (2015). "U-net: Convolutional networks for biomedical image segmentation". MICCAI.
- ↑ Zhu, J. (2017). "Unpaired Image-to-Image Translation using Cycle-Consistent Adversarial Networks". ICCV 2017.
- ↑ Choi, Y. (2017). "StarGAN: Unified Generative Adversarial Networks for Multi-Domain Image-to-Image Translation". CVPR 2018.
- ↑ "DCGAN for text-to-image synthesis".
- ↑ "Text-to-image synthesis with cGANs".
- ↑ Gauthier, Jon (2015). "Conditional generative adversarial nets for convolutional face generation". Cite journal requires
|journal=(help) - ↑ Antipov, G. (2017). "Face aging with conditional generative adversarial networks". 2017 ICIP.
- ↑ Villegas, R. (2017). "Decomposing Motion and Content for Natural Video Sequence Prediction". ICLR 2017.
- ↑ Nguyen, V. (2017). "Shadow Detection with Conditional Generative Adversarial Networks". 2017 ICCV.
To Add
For who is interested in the details of Pix2Pix, the paper [1] explains more in detail the generator and discriminator networks and other architectural choices. It also contains further examples of image-to-image translation, and funny translation such as edges to cats:

GANs have been found very useful in computer vision and computer graphic tasks. For non-expert readers, I suggest the wikipedia page on GANs and this simple web article on GANs.
- ↑ Cite error: Invalid
<ref>tag; no text was provided for refs named:2