Course:CPSC522/Inactive Cookie Mapping via Trail Matching
Inactive Cookie Mapping via Trail Matching
Principal Author: Dandan Wang
Abstract
Nowadays, online advertising industry is focusing more on how to turn annoying ads into useful information - Something Kind of Great. It is not surprised for online users to see that those ads match your interests. Many new technologies like Retargeting[1], Behavior Targeting[2] and Contextual Advertising[3] are created to satisfy the needs of both the ad clients and netizens.
To track netizens' online habits, the use of cookies is introduced. While for most of the online visitors consider this as an invasion of their privacy. They delete it, inactivate it and make ad systems face the difficulty that more and more useless inactive cookie visits are memorized in their servers. They take up spaces of ad servers, waste the data processing time and resources - inactive cookies are not doing anything good.
Hypothesis
Ip trail pattern performs better in improving the accuracy of inactive and active cookie linkage.
Builds on
The two algorithms introduced in this page are based on deterministic theory [4]deterministic theory of record linkage.
Related Pages
The idea of IP pattern matching is inspired from the paper below:
Jin, L., Li, C., & Mehrotra, S. (2003). Efficient record linkage in large data sets[5]. Eighth International Conference on Database Systems for Advanced Applications, 2003. (DASFAA 2003). Proceedings.
Introduction
Understanding Online Advertising

We must be familiar with online ads. They are everywhere, video ads - the first 5 seconds before a video on Youtube, banner ads, also Google Adwords[6] based on what you are searching for. It is not hard to find that it seems those ads know your interests. For instance, you searched a vacation to Vegas, and then you would see ads about hotel deals and cheap flights everywhere that you visit thereafter for the next several days. Why and how can they do this?
- For ad clients: make each impression worth the money, to help clients to either obtain a potential customer or push a purchase.
- For online visitor: broadcast information as relevant and useful as possible, instead of useless commercial ads.
- For advertising company: maximize the value of each impression.(i.e. ad company pay media by impression, but get paid from clients by click)
Cookie Tracking

Cookies are used to track visitors' online behavior. It is a small text file that placed in your browser when you surf online. Cookies are generally used to collect and store information related to your visit behavior, like website preferences, login information, or a user ID.
- When a visitor visits a page with advertising systems' tags(i.e. code) in it, the tag starts working. It would firstly check if this browser knows the current visitor or say is being tracked (i.e. if there is a cookie ID recorded in the browser, the server must have some visit history about this visitor) - if no, the server will create a new cookie ID and write in the cookie as a unique identifier of this visitor.Send request to Ad server, including dateTime, cookie ID, IP, URL, browser version, page category and also other information about this visit, and this piece of information will be recorded as a log in Ad server.
- The ad server display an ad either matches the interest of this visitor or not(i.e. if the server has no record about this user, then deliver ads for clients those targeting for expansion of awareness)
- Daily data processing(batch): Data management platform (aka DMP) analyzes all the log records once a day, and "paste tags" (i.e. different predictions like age group, interests) to visitors. (i.e. cookie IDs)By doing this, when this visitor again drops into any page within the ad network, the ad server would quickly match a most proper campaign or ad to this cookie id and display in a very short time manner.
Are they invading my privacy?
They are not targeting you as an individual, but a category - like age group, gender, interests, location - they do not know who you are, but predict what kind of people you are.
Inactive Cookie

You must have ever been persuaded to clear your cookie data, cache or browser history for this and that reasons but always around "privacy". Some browsers nowadays, even delete all the cookies after the current session ends. (i.e. every time when a user closes it.) Some experts and reports like Cookies – Invading Our Privacy for Marketing, Advertising and Security Issues[7]also try to educate netizens to learn to protect their privacy by clearing and inactivating cookies. Try to do so, and then you would find those useful "information" (i.e. ads) is gone, instead, you will see useless and boring ads like insurance, luxury cars and etc..
The old cookie ID (e.g. 2737496) in the browser is gone, instead, a new cookie ID (e.g. 2837593) is created and written in your browser. Consequently, the visit logs recorded in ad server regarding the old 2737496 would be useless - taking up memory spaces, wasting data processing time and resources - doing nothing good. But actually, those logs all refer to the same entity with new ID 2837593. The ad server no longer knows who you are until it obtains considerably enough information(i.e. online behavior) about you. But before this, you can see only "garbage ads".
Zombie Cookie
In order to solve the problem of cookie deletion, Zombie cookie was introduced in advertising industry in 2005. Those ad servers write flash cookies on Adobe Flash, and it can never ever be deleted. When a user deleted cookie data of a browser, the flash cookies will then rewrite the browser cookies - exactly the same as before, and this Zombie Cookie[8] will never die.
Because zombie cookie is hard to be deleted and kind of invading the user privacy, the use of flash cookie is then forbidden by most of ad exchange market like Google Double Click Ad Exchange[9]. (i.e. all the ad servers that interact with google is not allowed to plant zombie cookies)
Problem and Issues
To solve the problem of cookie deletion for Ad companies and improve the accuracy of behavior analysis, IP trail matching algorithm would be introduced in this page. Since there is no research previously regarding this topic, I would compare it with a simplified algorithm - most visited IP matching, to evaluate the performance of IP trail matching.
In this section, I will describe the terminology and original data structure. Let's generalize a simple model of the 2 IP-based de-duplication algorithms for a situation where cookies are deleted and newly created. To help to understand, let be a set of cookie IDs' tracking data imported from logs and be the set of entities' IP trail. For each user ID stores data in a table with attributes . For each record refers a piece of visit history of . At the same time, for each user ID stores data in a table with attributes . For each record refers the sum of each IP's visit times. The tables below are examples of the data structure described previously:
| DateTime | IP | URL | Browser Version |
|---|---|---|---|
| 2016-03-27 19:49:27 | 223.94.36.36 | http://www.domain.com/fresh/7291-0-0-0-0-2-0-0-0-0-0.html#trackref=sfbest_list_7299_menu_7291 | Mozilla/5.0 (Windows NT 6.1) |
| 2016-03-27 20:23:57 | 223.94.36.36 | http://www.domain.com/http://www.sfbest.com/fresh/313-0-0-0-0-2-0-0-0-0-0.html | Mozilla/5.0 (Windows NT 6.1) |
| 2016-03-28 10:11:23 | 223.94.57.58 | http://www.domain.com/http://www.sfbest.com/fresh/313-0-0-0-0-2-0-0-0-0-0.html | Mozilla/5.0 (Windows NT 6.1) |
| 2016-03-28 13:20:18 | 223.94.57.76 | http://www.domain.com/http://www.sfbest.com/fresh/313-0-0-0-0-2-0-0-0-0-0.html | Mozilla/5.0 (Windows NT 6.1) |
| IP | Times |
|---|---|
| 223.94.36.36 | 2 |
| 223.94.57.58 | 1 |
| 223.94.57.76 | 1 |
All user histories can be collected to construct an IP representative table , each refers to a track. The table is the result of data reconstruction of - with the sum of IP visit times, which is the common process and data structure of the 2 different algorithms.
Algorithm 1: Most Used IP
This algorithm is based on the thought that every person should have one place that he/she surf the most. 3 identifiers including browser version, active period (i.e. No timely overlap, which means we can only match those actives that created after the inactive cookie’s last visit.) and most used IP are used to determine the optimal combination.
IP Preprocessing
In some highly secured environment, IP addresses are dynamically allocated to different devices. For example, students in UBC access to UBC Wi-fi. Each time we re-access, the IP address varies but within the same subnet. For these IPs that belongs to the same subnet, we combine them together, form and record an IP class for those visits. For example, one cookie has visited 113.23.54.6, 113.23.54.45 and 113.23.54.123, instead of record each IP once, we count IP 113.23.54 as 3 times.
Input : IPs Output: IP clusters 1. end := arr.length 2. for i : =0; i < end; i++ : 3. for j := i + 1; j < end; j++ : 4. if arr[i].substring(0,arr[i].lastIndexOf(“.”)) == arr[j].substring(0,arr[j].lastIndexOf(“.”)): 5. shiftLeft := j 6. for k := j+1; k < end; k++, shiftLeft++ : 7. arr[shiftLeft] := arr[i].substring(0,arr[i].lastIndexOf(“.”)) 8. end for 9. end := end-1 10. j := j-1 11. end if 12. end for 13. end for
Update , sum the visit frequencies again, and record by IP clusters.
Data Reconstruction
Based on the data processing progress introduced in last section, we reconstruct the data presentation. Transform data from and inner join with and insert into either or . The reason why we divide cookie IDs into 2 different stream over the condition that if this cookie id appears during the last 15 days is that we collect and compare different attributes for the two categories to maintain the consistancy of cookie linkage. The table structures are shown below:
| Cookie ID | Most Visited IP | First Visit | Earliest Browser Version |
|---|---|---|---|
| 45906512377601798881 | 223.94.36.36 | 2016-03-27 19:49:27 | Mozilla/5.0 (Windows NT 6.1) |
| 45906512377601798882 | 113.23.54 | 2016-03-13 19:49:27 | Safari/537.36 |
| Cookie ID | Most Visited IP | Last Visit | Latest Browser Version |
|---|---|---|---|
| 45906501841205665571 | 60.212.78.76 | 2016-03-12 19:01:23 | Mozilla/5.0 (compatible; MSIE 9.0; Windows NT 6.1; Trident/5.0) |
| 45906501841205665592 | 113.23.54 | 2016-03-13 08:12:27 | Safari/537.36 |
First Visit VS Last Visit
We compare the first visit of active cookie with last visit of inactive cookie to make sure the matched active cookie is created after the deletion of the original cookie.
Earliest Browser Version VS Latest Browser Version
In the comparison of browser versions, we also consider the facts that people sometimes would or automatically update browsers. In these cases, a perfect match would ignore this kind of potential matches. We extract the earliest or latest browser version from logs for active and inactive cookies to make sure the active cookie has the same or higher browser version comparing with the potential linked inactive cookie.
Based on the deterministic record linkage theory, comparing and shown previously, it is apparent that user 45906512377601798882 and 45906501841205665592 have very high probability that they two refer to a same entity.
Algorithm 2: IP Trail Pattern

Algorithm 2 inspired from Efficient Record Linkage in Large Data Sets[5], which is a based on the basic methodologies of algorithm 1, but compares the IP trail pattern between each cookie instead of most visited IP, supposing that everyone has one's daily routine or habit of using the Internet. For instance, in the morning, people might surf the internet at home. After that, surf at school or work. Occasionally, have a cup of coffee at Starbucks, or lunch at your favorite restaurant. while when it is night, people go back home or to their cute girlfriends' or handsome boys'. This is more likely to be a reasonable habit of a visitor than the most visited IP. To form the pattern, it is not just the combination of the top 3 or 4 visited IPs, some other external influences need to be taken into considerations.
Noise avoidance
From the description in the last paragraph, we might find that surf at home, at work, at your girl friend's can be considered as pieces of the pattern - those IP visits happen more than others. But, how do we deal with those infrequent visits(e.g. cafes, restaurants etc..)? We consider those visits as noise and make the system automatically ignore them to avoid the influence over the IP pattern instead of waiting for frequent IP visits beat the infrequent ones, because if one has only limited IP pieces, the miss-formed pattern would never get matched from others.
VPN
There is another phenomenon that those influent visits vary from country to country. This is because of the use of VPN. How do we deal with those visits? ignore as normal noise? No. It depends. Some visits vary from one country to another might just because of a short trip, but a frequent variance between visits can be treated as a habit of using VPN and considered as a very important piece of the pattern.
Data Reconstruction
Algorithm 2 is based on the Algorithm 1, and the same as Algorithm 1, we need to firstly create two tables or . Avoid and discard the noise IPs and then determine if one specific user has the habit of using VPN labeling by 0 or 1. The attributes of the two tables are different from the Algorithm 1 in pattern piece attributes as below:
| Cookie ID | IP pattern 1 | IP pattern 2 | IP pattern 3 | VPN | Create DateTime | Earliest Browser Version |
|---|---|---|---|---|---|---|
| 45906512377601798881 | 223.94.36.36 | 223.94.57.58 | NULL | 0 | 2016-03-27 19:49:27 | Mozilla/5.0 (Windows NT 6.1) |
| 45906512377601798882 | 113.23.54.6 | NULL | NULL | 0 | 2016-03-13 19:49:27 | Safari/537.36 |
| User ID | IP pattern 1 | IP pattern 2 | IP pattern 3 | VPN | Last Visit | Latest Browser Version |
|---|---|---|---|---|---|---|
| 45906501841205665571 | 60.212.78.76 | 60.212.72.11 | NULL | 0 | 2016-03-12 19:01:23 | Mozilla/5.0 (compatible; MSIE 9.0; Windows NT 6.1; Trident/5.0) |
| 45906501841205665592 | 113.23.54.6 | NULL | NULL | 0 | 2016-03-13 08:12:27 | Safari/537.36 |
Compare the cookies in and , and form a mapping table.
Note: the comparison of IP patterns ignores the order of visit frequencies.
Experiments
We assessed the correct linkage rate of the two different algorithms over a huge data set, and the 10 subsets extracted from it. The test data is from 2 different Chinese online advertising companies(A and B), which contains 30-day visit logs that they collected from a B2C website during the same period. Company A uses regular cookies, and also have no solutions to inactive cookie problem, whereas company B plants flash cookies, so B have no problem with the deletion of cookies, their cookie ids are highly consistent.
Assume that both A and B are collecting data from the same environment in the same period without any data loss. (i.e. collect data from the same group of entities and recorded their every movement on the site) I applied both algorithm 1 and 2 to data collected by company A, and then compare with data collected by B, which tells the ground truth.
Test 1 is to apply both algorithms over the whole data set to compare the accuracy. Test 2 is to apply both algorithms 10 times, over different data sets, covering visit logs of 21 days, 22days,...,30 days respectively to check how the 2 algorithms perform over the time dimension.
The result of our experiment is shown below:
Test Results and Evaluation
Test 1
| Visit Records | Unique User ID | Correct Linkage | Ignored Linkage | Wrong Linkage | |
|---|---|---|---|---|---|
| Algorithm1 | 10,723,863 | 209,823 | 73% | 1.3% | 25.7% |
| Algorithm2 | 10,723,863 | 209,823 | 93.2% | 4.7% | 2.1% |
Clearly, algorithm 2 easily beats algorithm 1, which matches most of the inactive cookies with active ones correctly, but still some notable exceptions.
- The wrong linkage of algorithm 1 is very high, but seldom has ignored linkage, because it is very sensitive to changes, even one visit can change the matching result.
- The accuracy of algorithm 2 is far higher than algorithm 1(due to the neglecting of shared IP) and it requires a data accumulation for at least 2-3 days to form a reasonable pattern. In this way, miss matches are greatly reduced.
- Wrong linkages also happen 2.1% in algorithm 2 but is acceptable. The test data is from China. In China, 5% of people are university students, which means they are sharing same patterns with others.
Test 2
-
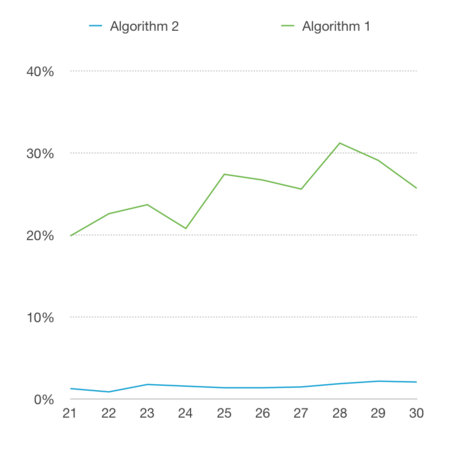 Miss Matching Rates
Miss Matching Rates -
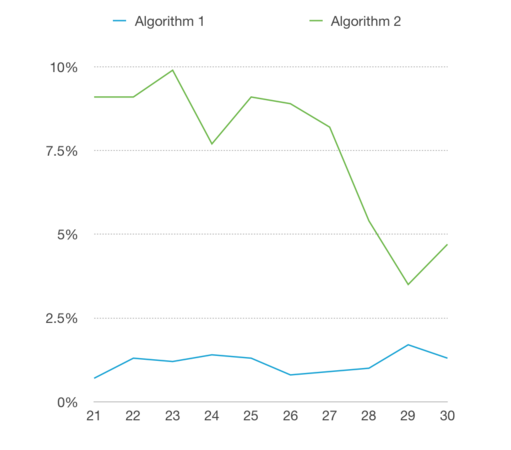 Ignore Rates
Ignore Rates -
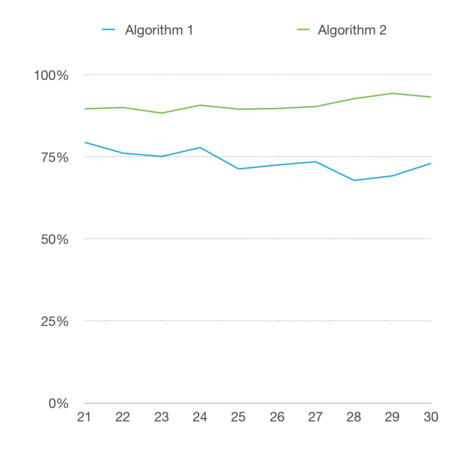 Accuracy
Accuracy



From the 3 graphs shown, we can see that the algorithm 2 still performs better than algorithm 1 overall.
- The miss matching rate of algorithm 2 is stable around 2% and is very low, no matter how the amount of test data varies. Algorithm 1 apparently performed poorly in this test, the miss match is very high and fluctuates. From this point, we can prove the talk previously that algorithm 1 is very sensitive to changes, it can easily make decisions, and also change decisions very quickly.
- The ignore rate of algorithm1 is low, which is because that it did not consider the shared IP address, and match inactive with active easily without collecting enough evidence. For algorithm 2, the ignore rate is much higher than that of algorithm 1, because algorithm 2 needs much more solid evidence to form patterns and match, hence, it increases the accuracy of record linkage.
- The Accuracy of algorithm 1 fluctuates - varies from 70 - 80%. The accuracy of algorithm 2 is stable and around 90%. Actually, this is satisfying, the accuracy not actually considered whether it matches correctly, but also the ignore rates. So the result of algorithm 2 is satisfying, which is much higher than that of algorithm 1.
Limitations
This page provides a theoretical exploration on how IP pattern would influence the cookie mapping across inactive and active cookie set on real-world data, but the test covers only one specific website instead of the overall situation without considering the press of servers for processing record linkage. The test result considered less than 5% miss match as admissible, but this 5% should be possible to overcome by future research.
For those browsers delete cookies after each session, it is hard to form a consistent pattern. A combination of Algorithm 1 and Algorithm 2 like the mechanism of para linkage would be studied to maintain the accuracy of record linkage but increase the sensitivity of cookie matching at the same time to solve frequent cookie deletion problem.
Conclusions and Future Research
The two algorithms provide a deterministic method for constructing a relationship between inactive and active cookies. The IP pattern matching methodology involves constructing IP trail patterns across different space and time from seemingly anonymous evidence of where a person visited, identifying the uniqueness of trail pattern and comparing between those relates inactive with active cookies.
This study of the IP pattern matching algorithm is important to the online advertising industry not only because it greatly improves the utilization of data collected from ad networks, reduces the waste of unnecessary memory space, but also increases the accuracy of behavior analysis. On top of solving cookie deletion problems, this methodology can also be applied in unique user identification across different devices, by dropping the comparison of browser and overlapped online behaviors.
However, this study is merely the beginning, and there are also several other areas (e.g. the advanced IP habit study, combining daily routine with IP, ) of research must be explored to help the expand the future studies. There exists still a lot of challenges in this research to achieve a higher accuracy closer to the truth and help ad servers to discard the using of zombie cookie to give the privacy back to netizens.
Annotated Bibliography
- ↑ Retargeting [1]
- ↑ Behavior Targeting[2]
- ↑ Contextual Advertising [3]
- ↑ deterministic theory [4]
- ↑ 5.0 5.1 Liang Jin, Chen Li, and Sharad Mehrotra "Efficient Record Linkage in Large Data Sets"
- ↑ Google Adwords [5]
- ↑ SOWMYAN JEGATHEESAN "Cookies – Invading Our Privacy for Marketing, Advertising and Security Issues"
- ↑ Zombie Cookie zombie cookies
- ↑ Google Double Click Ad Exchange' [6]
To Add
Put links and content here to be added. This does not need to be organized, and will not be graded as part of the page. If you find something that might be useful for a page, feel free to put it here.
|
|